With content courtesy of Cisco Systems
Last year I broke down the Cisco DNA – Digital Network Architecture in an article called “Beyond Marchitecture”, because quite frankly, it was a ton of marketing with little substance.
This year at Cisco Live! 2017, Cisco has done this the right way. With a new campaign, backed by the technical prowess we expect from Cisco and launched with all the big names, and big programs we expect. This was well thought out, and if this is what Chuck Robbins is going to bring to the table of Cisco Systems – there should be some big things ahead.
In a series of interviews with different business units, it was revealed that the “Handcuffs are off” and departments have been given the ability to innovate, collaborate and tear down the silos. This new program demonstrates that.
The Network. Intuitive.

First get past the grammar related issues of the new DNA Campaign, and realize that is it not “The Network Intuitive” it is “The Network. Intuitive.” – punctuation matters here
The key to understanding “The Network. Intuitive.” is in two powerful words.
Intent
As announced by Chuck Robbins in the Cisco Live keynote, they want you to power your network with business intent. No more programming VLANs, or setting up routing, but truly going into a unified console and telling it what you want to do.
“A computer will do what you tell it to do, that may be totally different from what you had in mind” — Quote Unknown
The idea that “Machine A” can talk to “Server B” and “User Y” and talk to “System X” without worrying about the underlying infrastructure is where they are going.
This is a construct, not a product, but unlike DNA-2016, there is a strong technical basis for this idea.
Context
Intent does not do you any good, unless you have context in your network. We need to understand, who is where, and understand what they are before we can set our intent against that object.
Chicken before the egg syndrome a little bit, how do we secure, route and prioritize our network, if we do not know what this traffic, who they are and what they are trying to do. Today context generally comes from things like IP Addresses and subnets. In DNA-2017, this context come from Cisco ISE.
The Network. Intuitive. InfoGraphic.
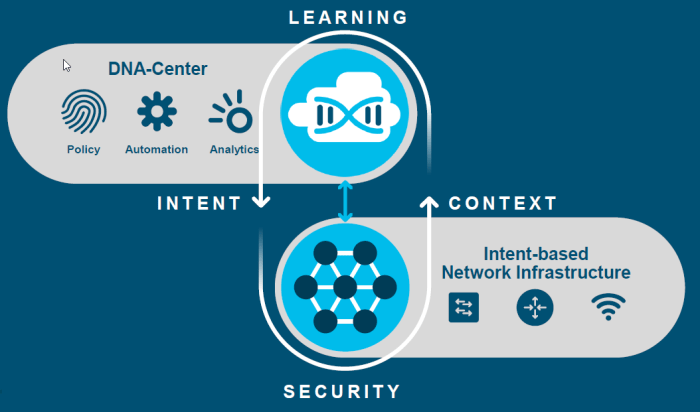
The latest info-graphic from Cisco really does provide a good overview of this new architecture.
The underlying technology for this new intuitive network technology is SD-Access – Software-Defined Access. This of “ACI – Application Centric Infrastructure” but now it is user centric – make our decisions and policies and apply them to users, and where they are is unimportant.
SD-Access Building Blocks

I want to help build the SD-Access story for you, so you can understand how this technology comes together. Like like years DNA announcement, SD-Access is a reference architecture, but there are bespoke technologies around it.
Transport Layer – Network
At the very basic transport layer, SD-Access relies on a few switch options that are available today. Supported on Catalyst 9K, 3650, 3850, 4500E, 6500/6800 and Nexus 7K. Wireless options are 3800, 2800, 1560 and controllers 8540, 5520 and 3504.
The new one to this party is the Catalyst 9000, developed by the team at Cisco with the new DopplerD series CPU with tons of power and supporting ETA – Encrypted Traffic Analytics. Please see my future blog post on the Catalyst 9000 series.
These devices do all the transport and implementation of policy in the background of SD-Access and move the bits around your network

Understanding the Campus Fabric
The underlay network will transport your traffic from place to place, this is what makes up your campus fabric. True virtual networking to the endpoints through encapsulation, not just through VLANs anymore. The idea is we want to segregate the forwarding plane, from the services plane, why should our physical network dictate how traffic flows around our network, but how can we add capabilities without massive complexity.

If you want me to sit here and admit that this is as easy as the old VLANs and IP addresses in your network – it simply is not. However the security, control and simplicity once it is implemented is worth it. The automation and contextual data you will receive.
The transport does not need to be complex, by using an overlay, we can deliver features through the overlay, and the underlay network, the hardware does not need to be complex.
LISP – Location Identity Separation Protocol – Layer 3
This bring together location and identity. Think of the old way for a moment, we know switch port, and IP address or subnet, and we have a weak idea of the context of a user, who and where they are. LISP takes the IP and Location and segregates them so that IP and Location are not tied anymore.
LISP is like DNS for packets, when a switch needs to forward packets from place to place, LISP identifies to the network device locations and the routes required using a map server or resolver. This could be an IOS device or a virtual machine somewhere. LISP allows a device to live in any place on the network. Getting in and out of the LISP environment is via a tunnel router or “XTR”.
This is what provides mobility of devices around your network, even if a user moves to another building or another floor, the IP address of that user does not change – they just move from place to place and the map system handles where that user is
VXLAN – Layer 2
Wait, why is VXLAN showing up in the access layer? Well, LISP is really a layer 3 technology, it ensures that packets can route, but what if we have users across multiple layer 3 areas that need layer 2 connectivity? What about multicast and broadcast traffic.
VXLAN provides the transport of our layer 2 traffic across our campus fabric.
Transporting Policy with Cisco TrustSEC
We can now add contextual information into the VXLAN headers through “SGT” or scale-able group tags. We need to use TrustSEC so that we can apply policies against objects but not based on their IP, but their identity. Instead of using the IP address, we use the SGT – tag to tell the rest of the network who owns this packet so we can make decisions based on security. SGT is applied by ISE and then access lists and rules are applied against security groups, users are placed in those groups within ISE.
Identity Layer – Context
This is where the context comes in. ISE – Identity Services Engine is used to create network identity for objects, users and systems. I know what some of you are thinking “Oh no – ISE”. Have you taken a look at ISE 2.1+ ? They have vastly improved the experience. There is no question that adding ISE will complicate your life, but it is the contextual engine that provides the data you need to secure your network. There is no avoiding ISE anymore, you will need to have it in your life, and your network.
There are benefits here, once ISE is implemented, all of your network devices start to see things are user activity, firewalls show users names not systems, you can start deploying policy against groups of objects and network authentication becomes very easy. Your wireless network becomes easier to manage from a security perspective.
Interface Layer – Intent
This is the real veggies. DNA Centre is the new package for the APIC-EM platform. This is Cisco’s single pane of glass attempt by Cisco so make a UI front end for your network, the intent is a single pane of glass for your ENTIRE network.

This is where your contextual groups from ISE like users and servers will meet up with the policy you want to create. There is no denying the interface is a little “Meraki” like, clearly they borrowed some design concepts. All of the complex components of SD-Access meet here in DNA Centre, and are then pushed out to the rest of your network. The automation from DNA Centre will automate everything for you. From dealing with ISE to programming those Catalyst switches. This is the automation layer. Set what intent you want, and automation will turn that into action down on your hardware layer. Worrying about all this VXLAN and LISP stuff? No worries, DNA Centre will help you here.

NDP – Network Data Platform
No shortage of data about our network, we have NetFlow and Syslog and any number of tools to deliver data. In the coming months as we get a better look into the new Network Data Platform, we will learn how this will help correlate network data and provide analytics. This is where the old “Proverbial lead into gold” promise is supposed to deliver. For me this is a wait and see approach, right now there just isn’t enough data out there, for now that is all I have to say. This is still very early.
More to come in future posts about Catalyst 9000 and DNA Centre, NDP and ETA.
With content courtesy of Cisco Systems