Back in August, at Networking Field Day 12 we had a very interesting presentation from ThousandEyes – my take away was excitement about what I saw, but I was cautiously optimistic because I have been told about these groundbreaking new tools before, so I held off, until I could actually go back and put this in a real production environment. Is this “Yet another tool” or can this deliver real value?
We have all been there, let me know if you have heard these complaints before
- The Network Is Down
- The Internet Is Slow
- <insert name of cloud product> is horrible
- Our Internet Performance to Site XX from YY is Poor – Fix it now!
The Network Is Down / Slow
This statement is universal – what people REALLY mean is, their perception of the network is poor. This could be caused by just about anything, poor server performance, poor application performance, saturated storage arrays, and yes it could also be the network. The problem is, why is “the network” the default gateway for blame? We cannot fix that mind set.

Cloud Complications
“The Cloud” complicates things for network resources, previously the internet was where you went to get things that did not belong to you. Now with services like Microsoft Office365, SalesForce, Azure and AWS – what was previously external is now used as an internal application, and while the application team is happy to offload their applications to a cloud provider or hosted application, it means that network resources are being forced to basically accept and support a series of routers/switches and infrastructure they have no control over.
Traceroute, Ping and Monitoring
Over the years we have all learned to use all sorts of tools to troubleshoot our networks. Traceroute came in 1988 and uses ICMP messages to probe a network and deliver information about responsive times to each hop along the way. 1988 is a long time ago.
The major problem with these types of tools is, they are probes, some use ICMP, TCP and even UDP to probe and test the network. Many of these tools do not detect things like tunnels and load balancers, and while your probe might show one route a different protocol might take a different route. They were designed for a different time, but yet most legacy tools use them.
The bottom line is – these tools do not provide you with complete data, without complete data you are making poor decisions. These tools commonly deliver inaccurate or incomplete path information.
ThousandEyes – Smarter Network Data
“Legacy products are built for controlled environments, ThousandEyes is designed for chaos” – Mohit Lad – CEO/Co-Founder – ThousandEyes
By deploying sensors all over the internet in a SaaS model, ThousandEyes brings together sensor data from all over the world. When you combine that with agents within your own infrastructure you start to get a very unique view and insight into performance and availability.
The Enterprise Agent provides you with an internal vantage point, performance of your ISP, your WAN, and application traffic. Stop me if you have heard this before, but here is the difference. Combine that with the many data centres and cloud agents that ThousandEyes deploys all over the globe, and you can now monitor, and troubleshoot global availability and performance.
Deployment of Enterprise Agents is very easy, deployed on any virtual platform, inside a Docker container, on metal in Linux, or even within a Cisco IOS Virtual Container. We deployed these in a matter of minutes and had data coming in within less than an hour.
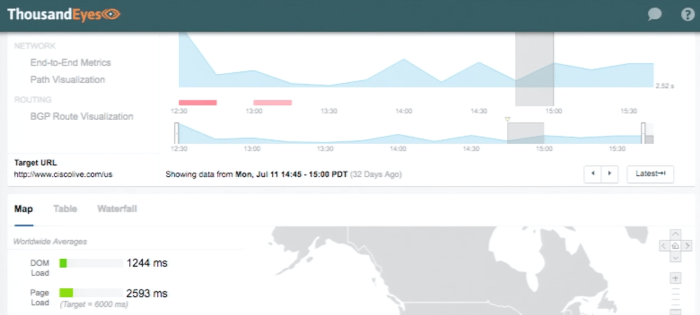
So above is a typical end of end metric for a web site – stay with me – lots of tools provide this, nothing ground breaking here. The problem is we don’t know WHY things are slow, next step? Blame the network. Not so fast.
Visualize Your Path
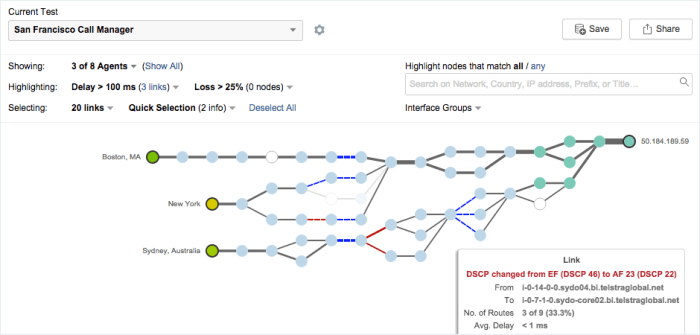
This would be your typical path visualization – but the tool built this – from the path of the probe, not a network map you provided. Realize that the hops in the middle, are not hops that you own or control – but using proprietary technology, ThousandEyes can probe, test and analyze the health, wellness and performance of those hops.
Catch your ISP
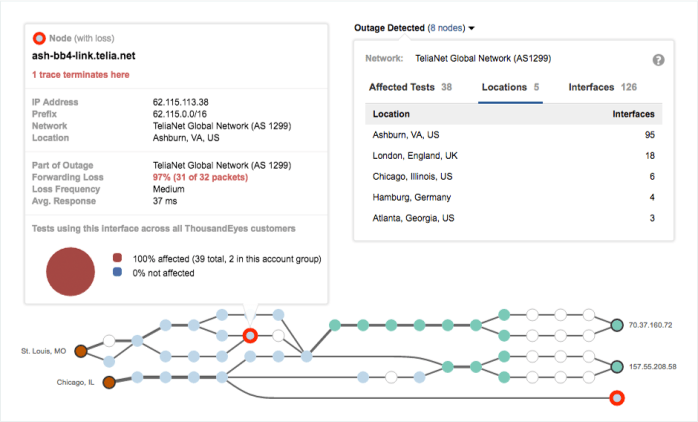
The above is a very typical scenario – people are calling, some users complain that things are slow, but some state things are just fine. Take the far end node, starting in 157. If you look, Chicago users would be fine, St Louis users would be sometimes fine, but that depends on the path their traffic takes.
No question this scenario would end up on the desk of the network engineer – and without a tool like this, it would be near impossible to pin point the problem, because the problem is intermittent. In this case I can call my ISP, and not only tell them the problem – I can even allow them temporary access to ThousandEyes if they want to see the data I have on their network.
Mean time to innocence? Minutes. Gone are the days where you check your infrastructure over and over again while the ISP feigns innocence.
Reverse Path? YES! – Still innocent!

Even reverse path can be troubleshot, in this case, due to issues beyond the network engineers control, and within the external network voice traffic is returning via multiple routes, and not all of them are healthy. This might result in chasing after your SIP provider, troubleshooting gateways, looking at your internal LAN. Open a ticket with the ISP and go grab a coffee Mr Network Engineer — this one isn’t you either.
Path Troubleshooting On Steroids
It is almost impossible for me to show you how great this is with still screen shots because you can zoom in and out, view individual nodes, look at peering – so here I have queued up the demo of the amazing path view capability courtesy of our team at Network Field Day 12, and a demo from Nick Kehpart – Sr Director for Product Marketing.
BGP Path Visualization and Internet Outage Detection
Again, No words on this – you have to see it. In this clip we show the BGP Path Visualization, the ability to see the path from one site to another – and figure out what exactly is going on across that path including troubleshooting BGP routing.
In this case Internet Outage Detection is used to detect packet loss – in the past – and troubleshoot now. Have you ever had someone say “yeah it was horrible yesterday but it is fine now” – wouldn’t it be great to be able to actually see what happened? Was it you? Was it someone else?
ThousandEyes Launches Endpoint Agent
This is big – in fact it is so big, one of our delegates literally jumped up in the middle of the presentation and screamed “TAKE MY MONEY” he was that excited about how much this was going to help him. The room was honestly full of people with their jaws down.
There are other vendors creating “end point” agents – but here is the difference – this one goes to network, it does not start off by blaming the network – it continues with the “Mean Time To Innocence” and helps to prove exactly where the problem is. The same level of detail we get with the entire ThousandEyes suite is extended all the way to the endpoint, and I can drill down, ALL THE WAY to BGP if I want, from application to network layer even WiFi and not only that – retrospectively.
Remember my comments about Cloud? It gets worse!
- Users working from home
- Users working from a hotel
- Public WiFi
- Corporate WiFi
- VPN
How are we supposed to find the true answer, and worse than that, normally the complaint is something like this
“So yesterday I was working in SalesForce and all of a sudden things were slow, I cannot get work done” – “Oh where were you?” – “I was using public WiFi at an airport in Anchorage” — the typical response is “I cannot troubleshoot that”
You can! With Endpoint Agent – we can look at end users in the home, at work, at public wifi, and compare them – is it really the application? Is it a large internet outage? Perhaps a few users just happen to be on poor wireless, what might look like something, might be a coincidence – but without data how do you know?
So how do we get it on workstations? You can push it out, it is lightweight and works as a browser plugin and a system service, the updates are all automatic and CPU consumption is less than 1% and less than 40mb of memory is ever used. The license is NOT NODE LOCKED – so you can move your licenses around, lets say you have 1000 users, but you don’t want to monitor them all, you could monitor a select 100, or perhaps you have a few users who complain all the time – you can push it only to them. Helpdesk agents could keep a few licenses on hand and deploy as necessary.
Endpoint Agent – DEMO
So before we get into the demo – we start with this, client computer, they are on WiFi, they have internet – oh look, a proxy and the internet site on the far end.
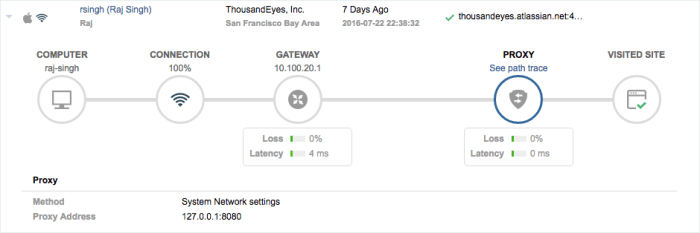
The bottom line – I cannot explain this in a blog – the only thing I can tell you is – you have to see it to believe it. In this demo they will show you a real scenario for what it looks like when troubleshooting real issues. The key word here is DRILL DOWN!

[…] ThousandEyes – Mean Time to Innocence in minutes […]
LikeLike
[…] ThousandEyes – Mean Time to Innocence – by Justin Cohen […]
LikeLike