
Cisco is unwrapping the covers on Hypeflex. Their direct and targeted attack on the hyperconverged market.
The headlines are basically this….
- A true hyperconvered system that includes network connectivity
- Built on the tried and true UCS platform
- A revolutionary storage system
- No new administrative platform – a plug in with VCentre
- Competitive with other offerings
- Tested and proven today
- Actually turns up in an hour.
What does it look like?

The story is much as you have seen in the past. Server based platform, with on board disk. However remember, hyperconvergence is about using “commodity” hardware with onboard DAS disk in order to deliver converged type infrastructure for lower cost with easy expand-ability.
The system will launch with VMWare day 1, with other hypervisors and container support down the road.
The Secret Is In The Storage
The secret sauce with all hyperconverged solutions is in the storage layer, and Nutanix has always pried themselves on being the leader here, and they are, with developers from top tier companies they built a very mature product with demonstrated performance. Many others have tried to meet or beat this performance and they continue to be the market leader – HyperFlex plans to challenge that.
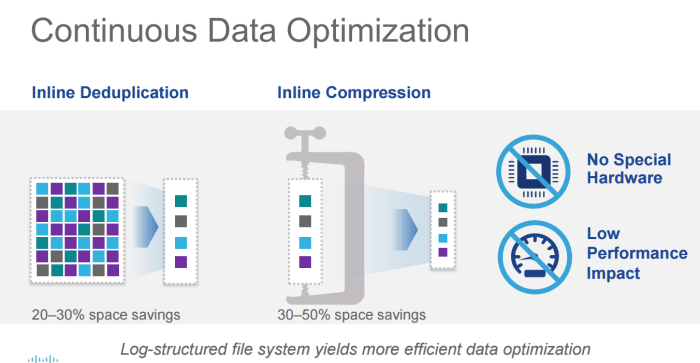
Cisco had to differentiate themselves. By using a log based file system, with intelligent caching they have eliminated the 3-phase commit performance problems. Basically with a 3 phase commit, we have to make sure that data is sent to all nodes before it’s committed as written. Cisco eliminates that by log shipping and caching. I am sure we will get more details as this moves on, and I will admit to not being a storage architect but the secret sauce is in the software.
De-duplication and Compression is all the rage, and they are delivering it here – with low performance impact. The technical experts tell me – this is all around their caching technology. Are you seeing a trend here?
What does this look like?

The Fabric Interconnect is right there on top – and HyperFlex is built on UCS – so the FI is how we control the hardware, manage nodes and provide the network. HyperFlex will deliver where other hyperconverged companies have not – in the network. While others tell customers “we use your network” – Cisco recognizes the important of engineering, and when building hyperconverged – the network is way too important to leave to the end users, the performance between nodes must be high, and predictable. The UCS Fabric Interconnect is perfect for this task. Why re-invent the wheel on connectivity, the FI delivers features and performance.
There will be a flexible deployment model – list prices around $59K USD to start, which is competitive – and you can build with balanced, capacity heavy or compute heavy nodes, or a mixture to create your own custom environment.
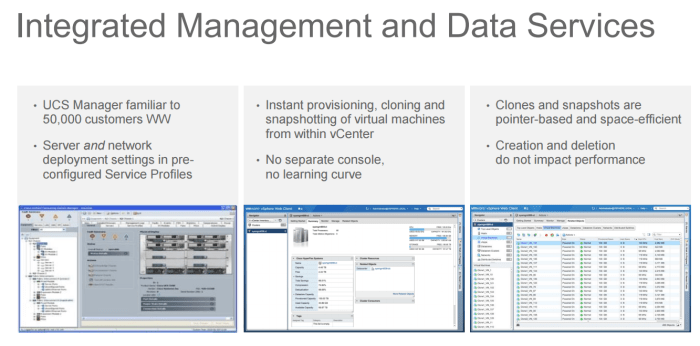
The administration is about familiarity here, with the hardware being managed by the very familiar and manageable UCS Manager, and the hyperconverged part being managed with a plug in to VCentre. No extra management portals or parts required. This means time to value is fast, and time to market is also fast and chances are you will not any training to work on this thing.

So where does this fit? Well, it’s a whole new product line – but the pedigree of UCS is there, so the trusted and hardened UCS platform is right there – and it fits into the core data centre portfolio.
Independent Scaling
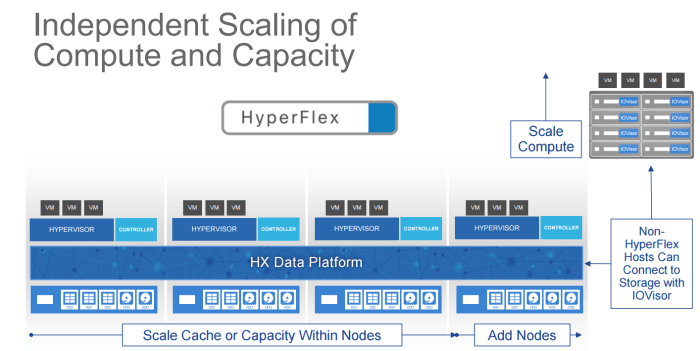
Expanding hyperconverged you need flexibility (HyperFlex?) and sometimes clients just want to add compute. Luckily using IOVisor, you can actually access the storage from non HyperFlex hosts using their IOVisor software. There is many instances when accessing this storage could be useful, call it migration or disaster recovery, or high availability. For all the reasons we cannot think of this type of flexibility is great.
Each node has a “controller” which handles the local node, and mostly storage activities and manages the cache on that node. Just like other platforms.
Failures
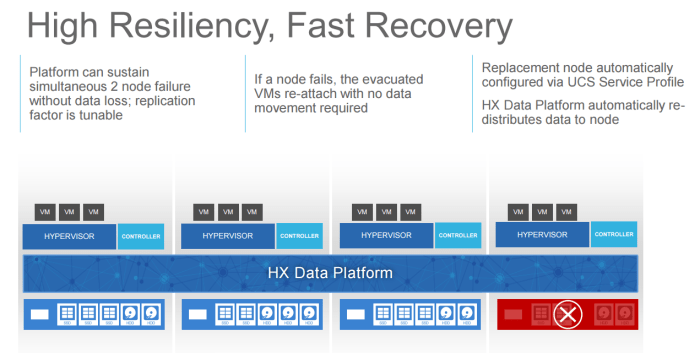
The system can handle two node failures, and because it’s built on service profiles, node replacement is obviously very easy. As soon as the replacement node comes up, data replications begins immediately over the high performance built in network.
Where do you find out more?
http://www.cisco.com/go/hyperflex
That’s a wrap! Looking forward to getting my hands on this thing, if anyone was going to take a shot at this market – it’s Cisco and I cannot wait to get my hands on it.
